Ground Truth Labels and In-context Learning
27 Feb 2023With the introduction of pre-trained models and their adaption to downstream tasks (Howard & Ruder, 2018; Devlin et al., 2019), the natural language processing (NLP) field has had its imagenet-moment. Moreover, in-context learning (ICL) (Brown et al., 2020) has proven to be another great game-changer on top of pre-trained languages. However, not a lot of work has gone into exploring why ICL works and what elements are crucial to its performance. In this blog post, I go over some literature exploring why, how and when ICL works (Min et al., 2022; Yoo et al., 2022; Wei et al., 2023).
Background
A few years ago, taking advantage of pre-trained languages became the way to approach a new task; by either adapting knowledge or fine-tuning the pre-trained model (Howard & Ruder, 2018; Peters et al., 2018) you could achieve state of the art performance. The battles of pre-trained languages, with their growing sizes began.
In 2020, (Brown et al., 2020) introduced what they call in-context learning (ICL) as a concept for sufficiently large models. The authors propose GPT-3, a model trained on a causal language modeling task on massive amounts of data. The resulting model shows the ability of ICL. ICL consists on models getting a prompt with instructions for the task to be carried out. Additionally, examples of the task done successfully can also included. The performance of ICL is suprisingly good and best of all: no parameter updating happens.
The Premise
We will first look at in-context learning as presented originally (Brown et al., 2020). Figure 1 shows a sample input illustrating how in-context learning is usually done. Generally a task description is included, examples can be included, and finally a prompt with the input for which a prediction is desired.

The original paper calls this specific input an example of few-shot in-context learning. From this example we can infer that we can study at least the following aspects of ICL:
- Input-label mapping
- Distribution of inputs
- Label space
- Format of input
This blog post will discuss all of them, but will focus on the first one the most.
How does it work?
The overall mechanism of ICL is not well understood and many questions regarding why and how it works remain to be answered.
That said, recent studies (von Oswald et al., 2022; Dai et al., 2022) have shown that internally, the model mimics a gradient descent approach via its attention mechanism to learn from the input prompt. This conditions the model to “learn” from the input and thus generate the right output.
However, understanding how exactly the input influences the ICL mechanism and what truly matters is something that will be explored further in this blogpost.
What Matters: The Claim and the Semi-Refutal
It has been historically assumed that a good set of examples is important for good ICL performance (Liu et al., 2022; Lester et al., 2021). However, what makes a good example remained to be explored. A recent study (Min et al., 2022) proposed what is important in a prompt.
The Claim
In their paper (Min et al., 2022) the authors explored 6 large language models (LLMs), ranging from 774 million parameters (GPT-2) to 175 billion parameters (GPT-3, see Table 1 for a full list of models evaluated). Two inference methods were tried: direct and channel. 6 different tasks were evaluated: sentiment analysis, paraphrase detection, sentence completion, NLI, hate speech detection, question answering. These tasks were evaluated on 26 datasets total.
| Model | # Params | Public | Meta-trained |
|---|---|---|---|
| GPT-2 Large | 774M | ✔️ | ✘ |
| MetaICL | 774M | ✔️ | ✔️ |
| GPT-J | 6B | ✔️ | ✘ |
| fairseq 6.7B | 6.7B | ✔️ | ✘ |
| fairseq 13B | 13B | ✔️ | ✘ |
| GPT-3 | 175B | ✘ | ✘ |
Table 1: Models analyzed (Min et al., 2022)
The authors ran experiments in a \(k\)-shot setting, where they set \(k=16\) and ran each experiment on five different seeds. They used \(F_1\) and accuracy as their reported metrics. Their finding were as follows:
Input-label Mapping: the main result of the paper shows that assigning random labels (as opposed to the ground-truth labels) in the examples of the input has no significant impact to the ICL performance.

Number of [correct] labels: The effect described above seems to be consistent, regardless of what \(k\) is picked. See Figure 3. Experiments also show that after a certain \(k\) performance does not improve greatly.

Why it works (other factors):
As previously mentioned, the authors explore other factors such as: label space, format and distribution of inputs.
Figures 4, 5 and 6 show their findings with respect to distribution of inputs, format, and label space respectively.
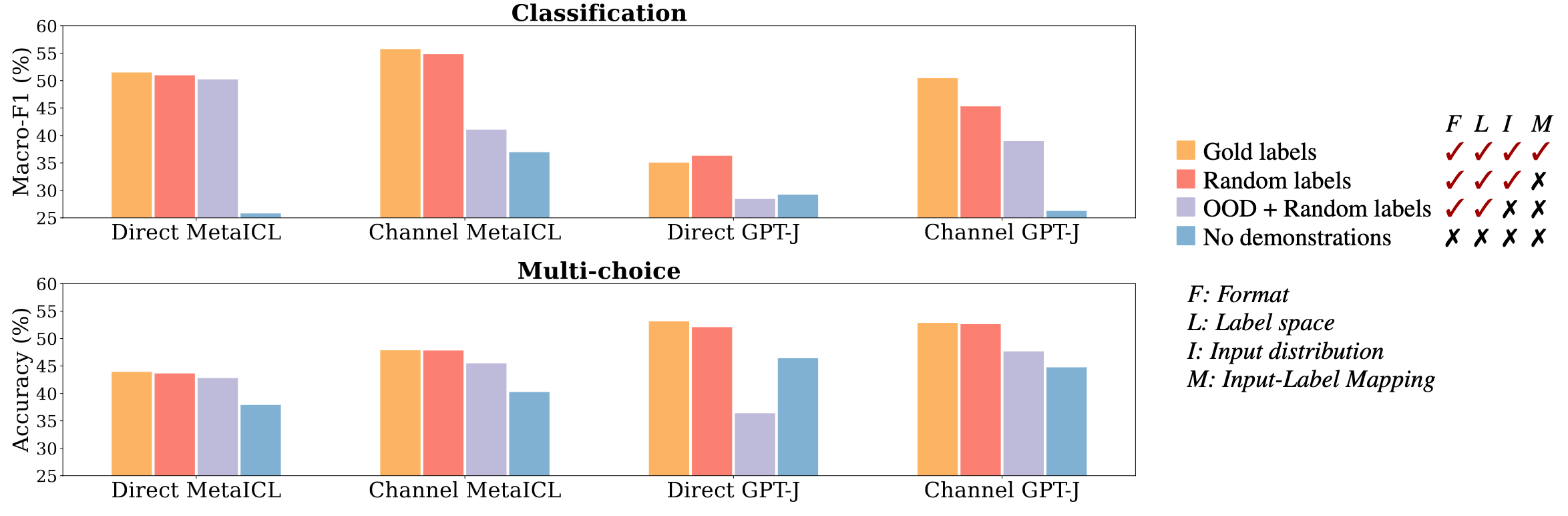

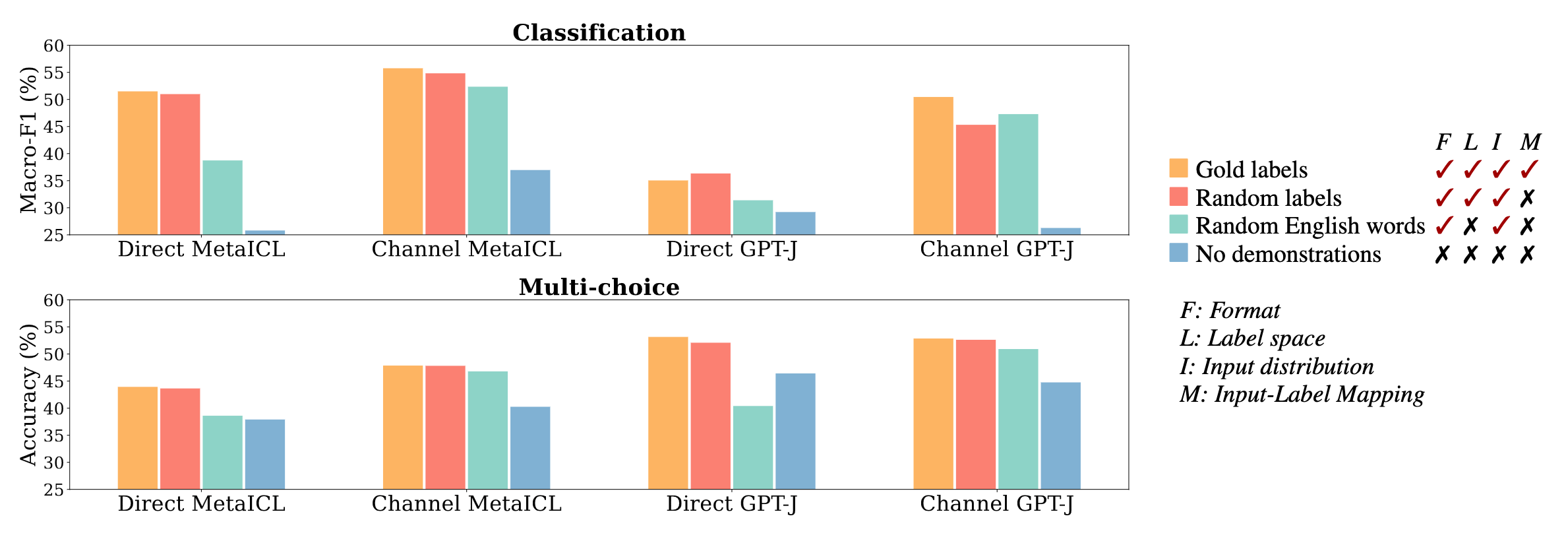
Briefly, they find that showing the label and input distribution, even if it is just independently, i.e. now showing a direct mapping, is crucial for ICL. If one of these aspects if missing but the right format is used, performance can still remain high.
The Semi-Refutal
With NLP moving so fast, such bold claims would not go unchallenged. In the same conference where the above paper was presented, a response paper (Yoo et al., 2022) already showed up challenging and refining the experiments presented to show that ground-truth labels do [sometimes] indeed matter. Figure 7 shows a case where ground-truth labels in the input clearly matter.
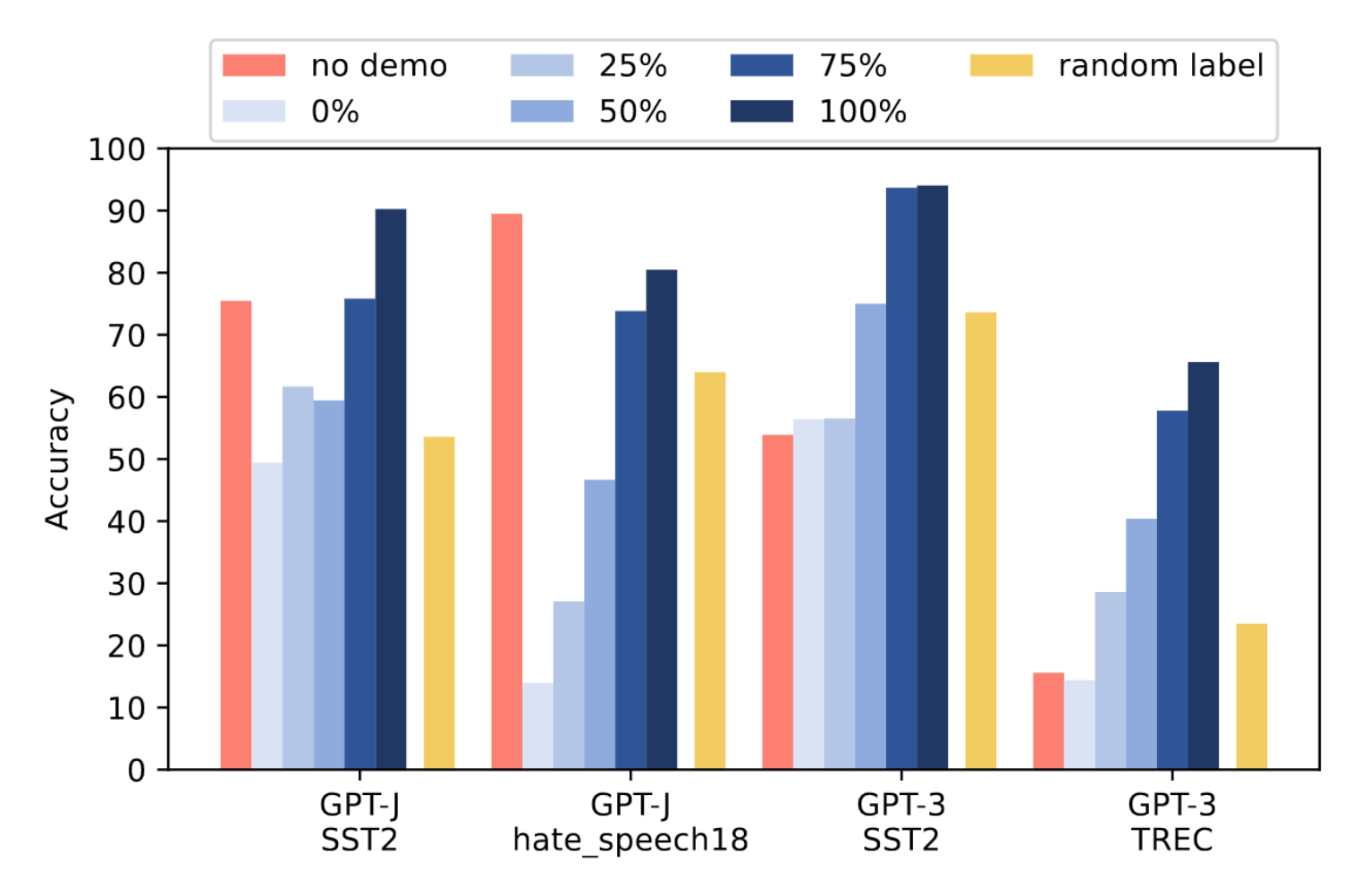
The authors of this work aim to propose more systematic metrics and experiments to analyzing this phenomenon. The authors use mostly the same tasks and datasets. Additionally, however, they propose the following.
Label-correctness Sensitivity: We’re not just interested in whether models are sensitive but how sensitive they are to label corruption. Thus, the authors define sensitivity as the slope to the modelling of the decaying performance as labels get corrupted:
\[y = \beta_0 + \beta_1 s\]Where \(y\) is the obtained performance as measured by e.g. accuracy. \(s\) is the percentage of correctly labeled examples in the input. This would thus make \(\beta_1\) our sensitivity measure.
Ground-truth Label Effect Ratio: Not all tasks are made the same. Some are easier than others for ICL. Thus, the authors define a way to measure the impact of label corruption, or rather how much ground-truth labels improve performance over random labels.
\[GLER = \frac{y_{GT} - y_{RL}}{y_{GT} - y_{\emptyset}}\]Where \(y_{GT}\) is the performance using ground-truth labels, \(y_{RL}\) is the performance of the model using random labels and \(y_{\emptyset}\) is the performance of the model in a zero-shot setting, i.e. no examples provided in the input.
This basically tells us how much ground-truth labels improve performance over random labels.
Main Results
Initial results
Table 2 shows how there is a clear positive correlation, i.e. there is sensitivity towards label corruption.
| Method | Coefficient | Intercept | \(R^2\) |
|---|---|---|---|
| GPT-NeoX Direct | 0.300 | 0.327 | 0.810 |
| GPT-J Direct | 0.309 | 0.291 | 0.861 |
Table 2: Main results for regression fitted as per the sensitivity equation provided.
Additionally, figure 8 shows sensitivity and GLER results for the different datasets and tasks.
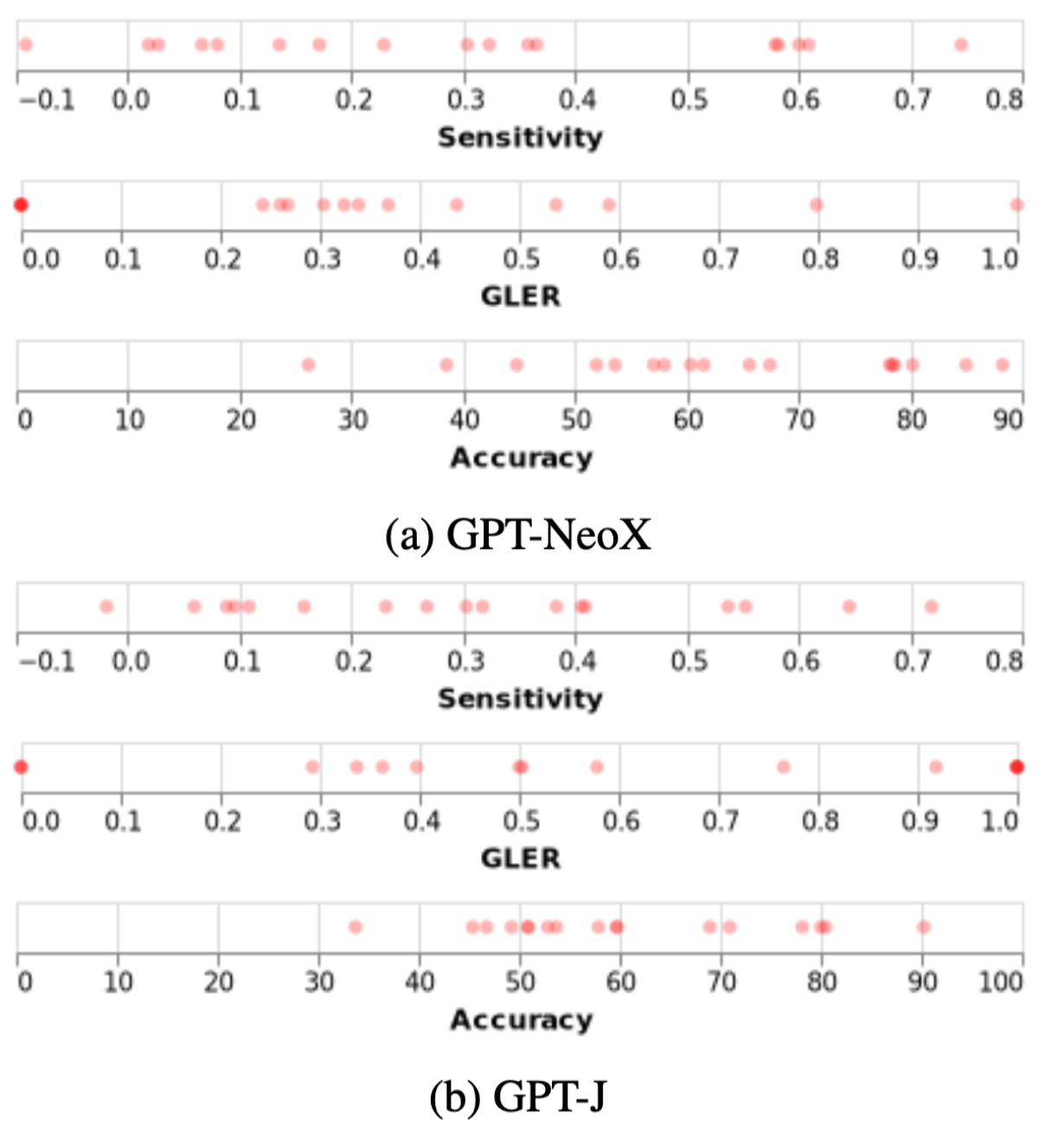
Task difficulty: the authors hypothesize that sensitivity is related to task difficulty. They propose the following metric and present the results in figure 9.
\[y_{rel} = y_{GT} - y_{baseline}\]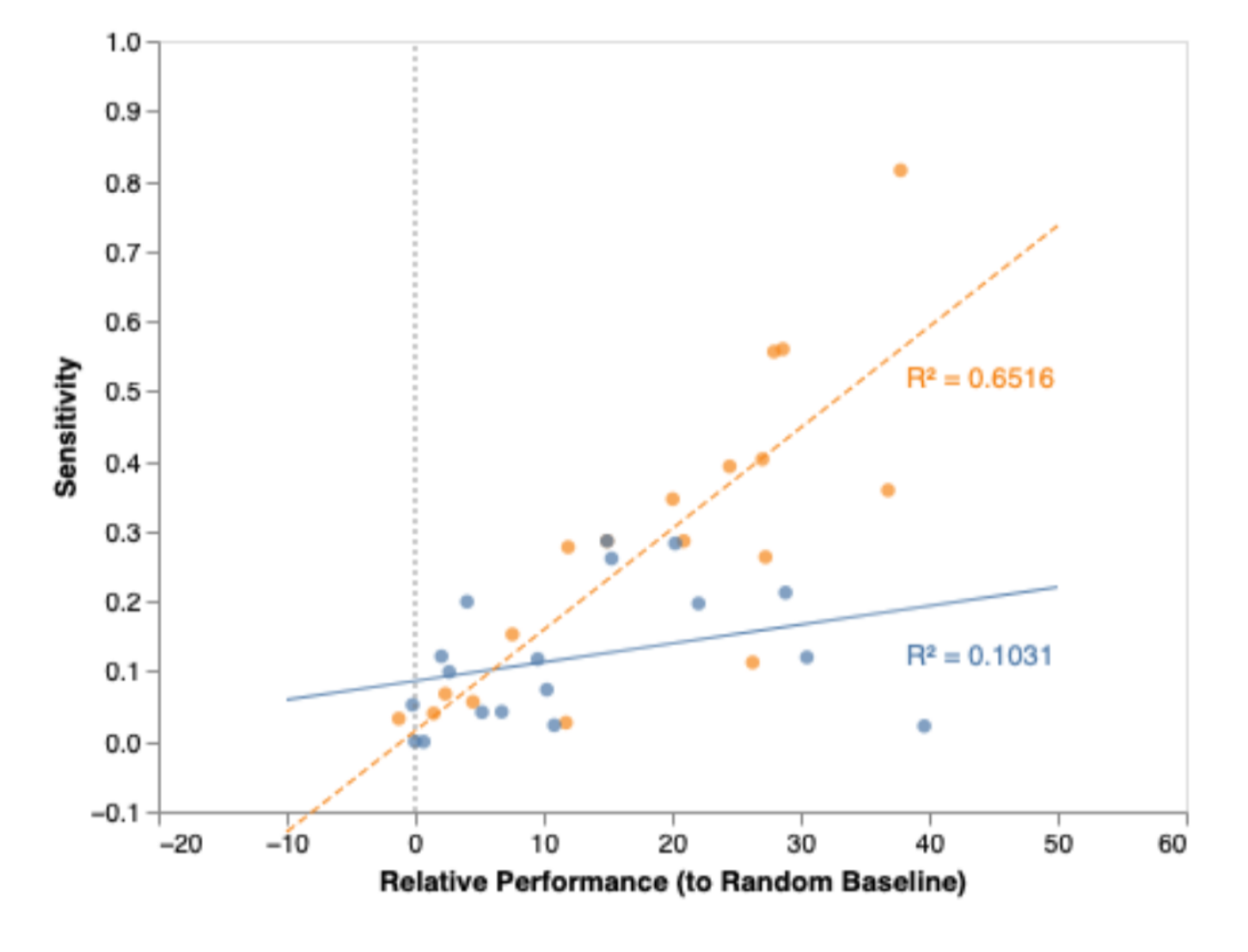
The authors conclude that sensitivity alone is not a powerful enough metric on its own. Something like task difficulty must also be taken into account.
When do ground-truth labels [not] matter?
The authors also suggets scenarios and factors where sensitivity may be reduced:
- Using the channel method of inference as opposed to direct
- Calibrating before using (Zhao et al., 2021) might also reduce sensitivity
- The higher your \(k\) the more sensitive your model will be to some degree
- They also show how the model size be positively correlated with sensitivity
Recent Discoveries
Aligned with the results regarding size of model discussed (Yoo et al., 2022), more recent work (Wei et al., 2023) has shown that not only are larger models more sensitive to label corruption, but also that they process ICL differently as they scale up. Emergent abilities are once again relevant here.
The main findings are as follows:
- Models get better at overriding semantic priors as they get larger, i.e. they’re better at “following” the input-label mapping in the input.
- Being able to use semantically unrelated labels is also an emergent ability. While (Yoo et al., 2022) also studied this, the scale of the models they used for this particular experiment were not sufficiently distinct to show this effect.
- Instruction tuned models improve at making use of semantic priors and also to make use of input-label mapping. However, the former is stronger than the latter.
Figures 10, 11 and 12 show these results in more detail.
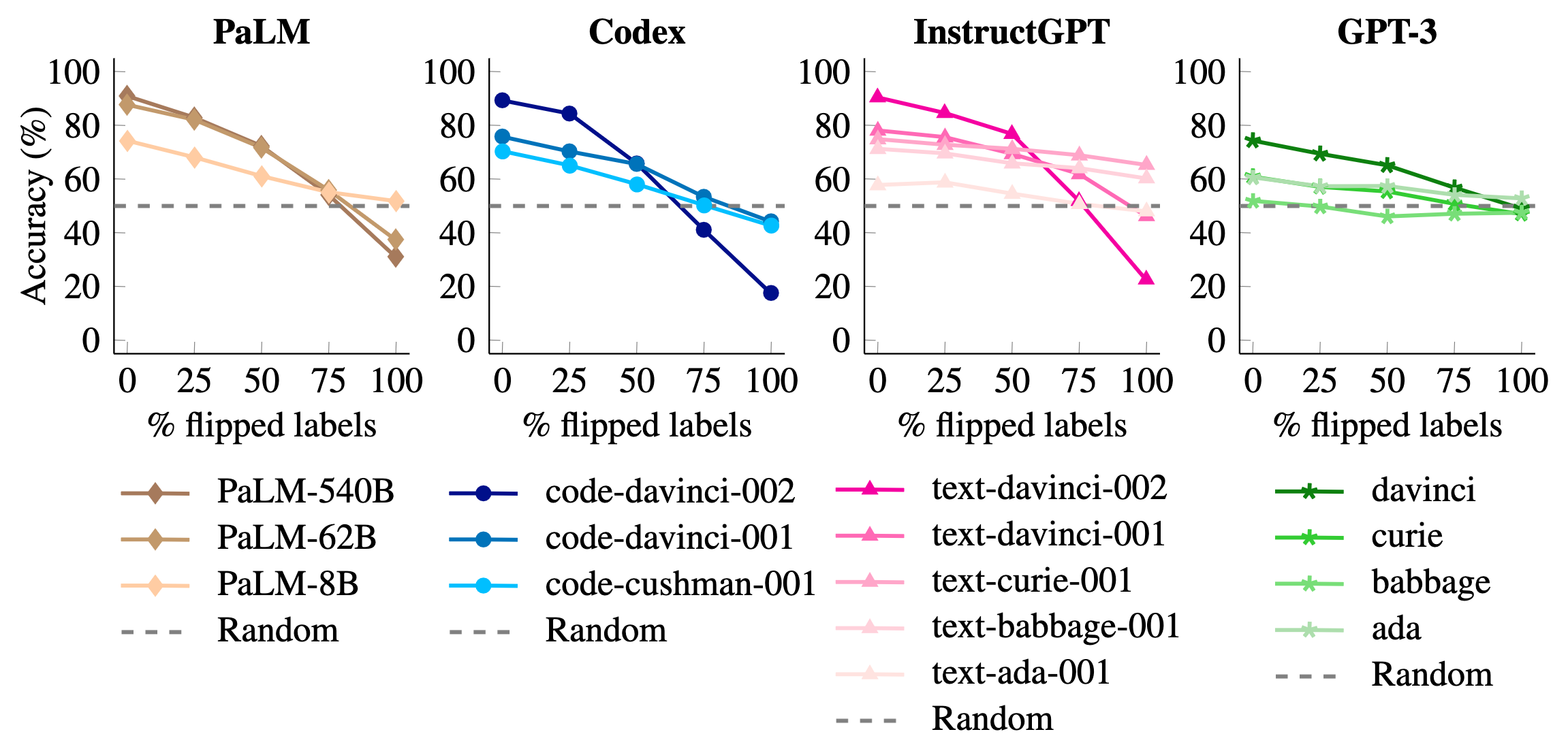
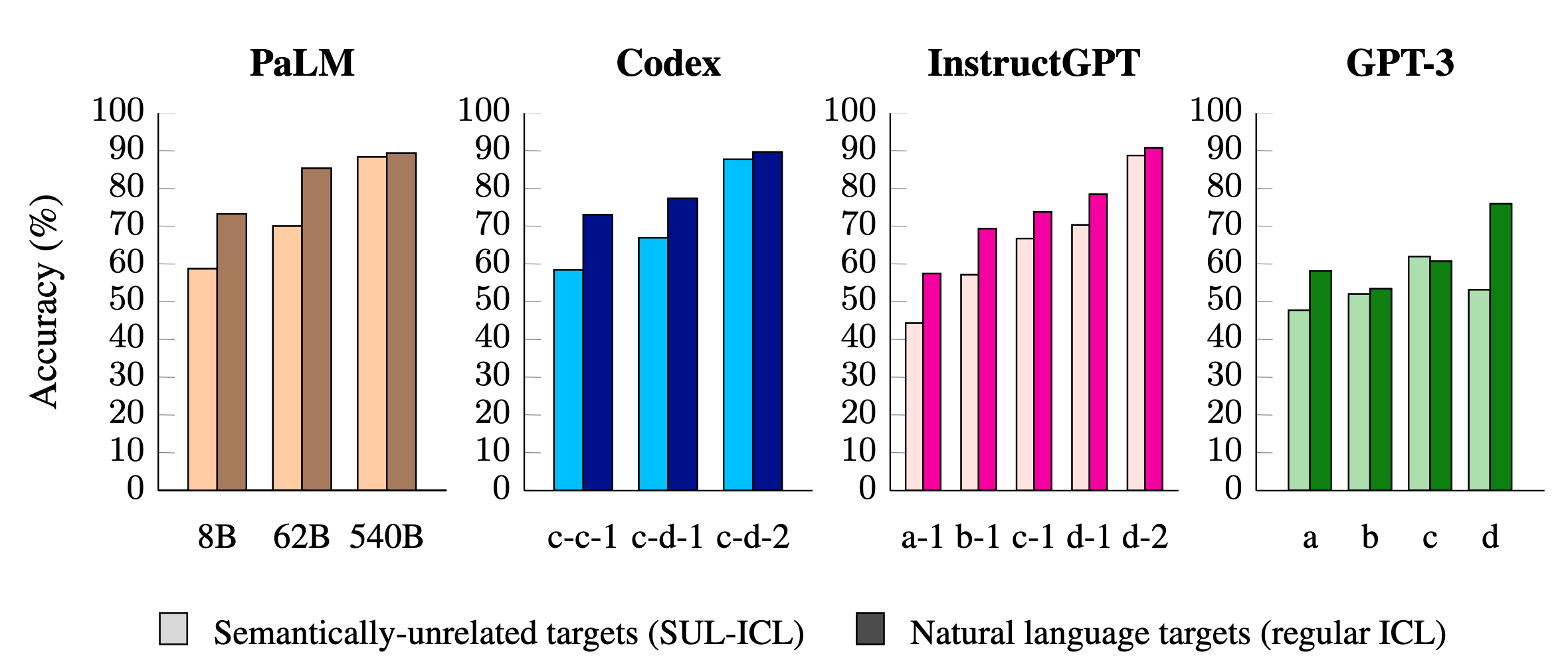
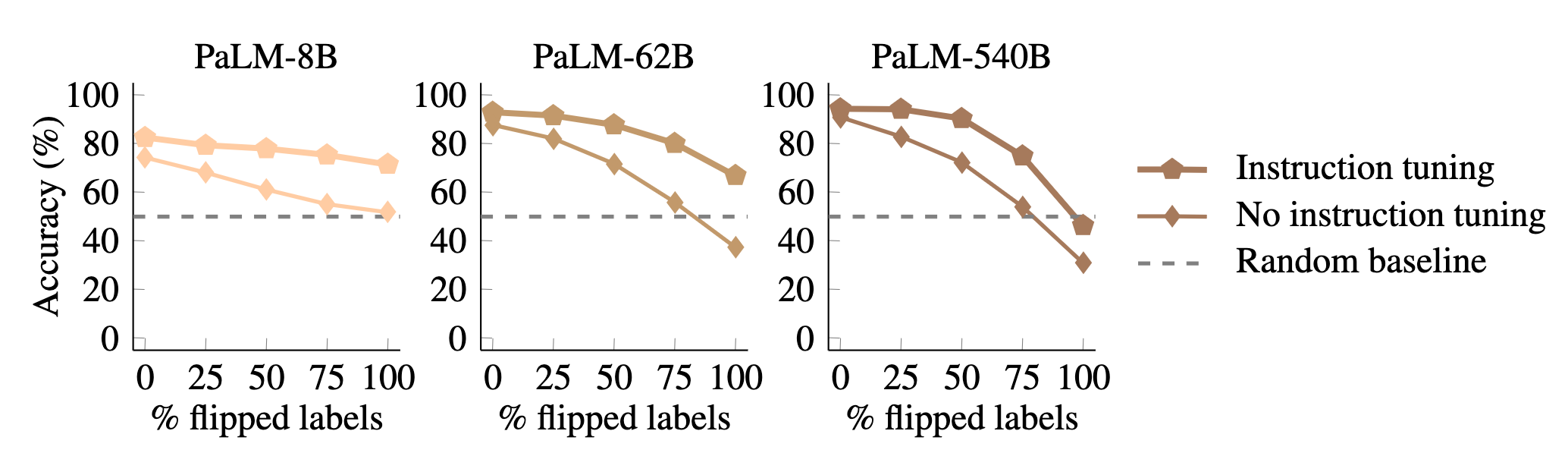
Conclusion
Understanding in-context learning, how, and why it works has shown a lot of progress in the past few months. Through the works discussed here, we can conclude that models are indeed sensitive to label corruption in the input. However, this does not always hold. This is particularly relevant for smaller language models.
Large language models are stronger at overriding semantic priors they have seen in their pre-training and following the input-label mapping in the input. They are even capable of making use of semantically unrelated labels used in the input.
References
- Howard, J., & Ruder, S. (2018). Universal Language Model Fine-tuning for Text Classification. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 328–339.
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4171–4186. https://doi.org/10.18653/v1/N19-1423
- Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D., Wu, J., Winter, C., … Amodei, D. (2020). Language Models are Few-Shot Learners. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, & H. Lin (Eds.), Advances in Neural Information Processing Systems (Vol. 33, pp. 1877–1901). Curran Associates, Inc. https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf
- Min, S., Lyu, X., Holtzman, A., Artetxe, M., Lewis, M., Hajishirzi, H., & Zettlemoyer, L. (2022). Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 11048–11064. https://aclanthology.org/2022.emnlp-main.759
- Yoo, K. M., Kim, J., Kim, H. J., Cho, H., Jo, H., Lee, S.-W., Lee, S.-goo, & Kim, T. (2022). Ground-Truth Labels Matter: A Deeper Look into Input-Label Demonstrations. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 2422–2437. https://aclanthology.org/2022.emnlp-main.155
- Wei, J., Wei, J., Tay, Y., Tran, D., Webson, A., Lu, Y., Chen, X., Liu, H., Huang, D., Zhou, D., & others. (2023). Larger language models do in-context learning differently. ArXiv Preprint ArXiv:2303.03846.
- Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018). Deep Contextualized Word Representations. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), 2227–2237. https://doi.org/10.18653/v1/N18-1202
- von Oswald, J., Niklasson, E., Randazzo, E., Sacramento, J., Mordvintsev, A., Zhmoginov, A., & Vladymyrov, M. (2022). Transformers learn in-context by gradient descent. ArXiv Preprint ArXiv:2212.07677.
- Dai, D., Sun, Y., Dong, L., Hao, Y., Sui, Z., & Wei, F. (2022). Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta Optimizers. ArXiv Preprint ArXiv:2212.10559.
- Liu, J., Shen, D., Zhang, Y., Dolan, B., Carin, L., & Chen, W. (2022). What Makes Good In-Context Examples for GPT-3? Proceedings of Deep Learning Inside Out (DeeLIO 2022): The 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, 100–114. https://doi.org/10.18653/v1/2022.deelio-1.10
- Lester, B., Al-Rfou, R., & Constant, N. (2021). The Power of Scale for Parameter-Efficient Prompt Tuning. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 3045–3059. https://doi.org/10.18653/v1/2021.emnlp-main.243
- Zhao, Z., Wallace, E., Feng, S., Klein, D., & Singh, S. (2021). Calibrate before use: Improving few-shot performance of language models. International Conference on Machine Learning, 12697–12706.